
為什麼要用本地 LLM? #
當你已經開始習慣用 ChatGPT 或其他雲端 LLM(大型語言模型)時,或許會問:為什麼還有人要自己下載、安裝一個「本地 LLM」在電腦上呢?
原因其實很簡單——隱私、速度與彈性。 使用本地 LLM,你的對話內容完全保留在自己電腦,不必擔心敏感資料被上傳到雲端、被第三方分析或收集。更棒的是,本地 LLM 支援離線運作,沒有網路時也能照樣幫你寫程式、翻譯、產生內容,有時候反應速度可能比連雲端還快。再來,開源本地模型通常允許你客製化參數、安裝外掛,甚至調整語言風格,比商用服務有更多可玩性和自主權。
所以,對於重視隱私、需要離線支援,或想探索 AI 進階應用的人來說,local LLM 是一個不可忽視的選擇!唯一要注意的一點是:你使用的顯卡效能和記憶體需求可能不小。
Ollama #
Ollama 是一款近年非常受歡迎的本地 LLM 執行環境,它讓你可以在自己的電腦上輕鬆運行各種主流的大型語言模型,例如 Llama 3、Phi-4、Gemma-3 等等,不需要複雜的設定或是難懂的程式語言。而且Ollama是跨平台的,無論是 Mac、Windows 還是 Linux,只要一條指令就能安裝,幾分鐘內就能開始和 AI 對話、產生文字、寫程式、總結資料等。
此外,Ollama 支援下載不同體積、不同特性的模型,讓你可以根據自己的需求和硬體選擇合適的 AI 助手。對於注重隱私、效率和客製化的人來說,Ollama 是體驗本地 LLM 最方便、最親切的入門選擇之!
安裝 Ollama #
Windows 使用者 #
在此下載
Mac 使用者 #
在此下載
Linux 使用者 #
curl -fsSL https://ollama.com/install.sh | sh
其他方法 #
參閱 Ollama 的官方 GitHub repo
下載LLM 模型 #
安裝完 ollama 後,下一步就是要挑選喜歡的 LLM 模型來運行。不同的 LLM 模型往往有不同的優缺點,沒有說哪一個模型最優秀。不過一個簡單的概念是如果模型使用越多的參數,往往越強大,但是使用越多的參數,運行的速度就越慢,也需要越大的記憶體,這一點大家需要看自己的記憶體來嘗試。
-
在官方網站下載
Ollama 官方網站裡面有非常多的 LLM 模型可以挑選下載,譬如:
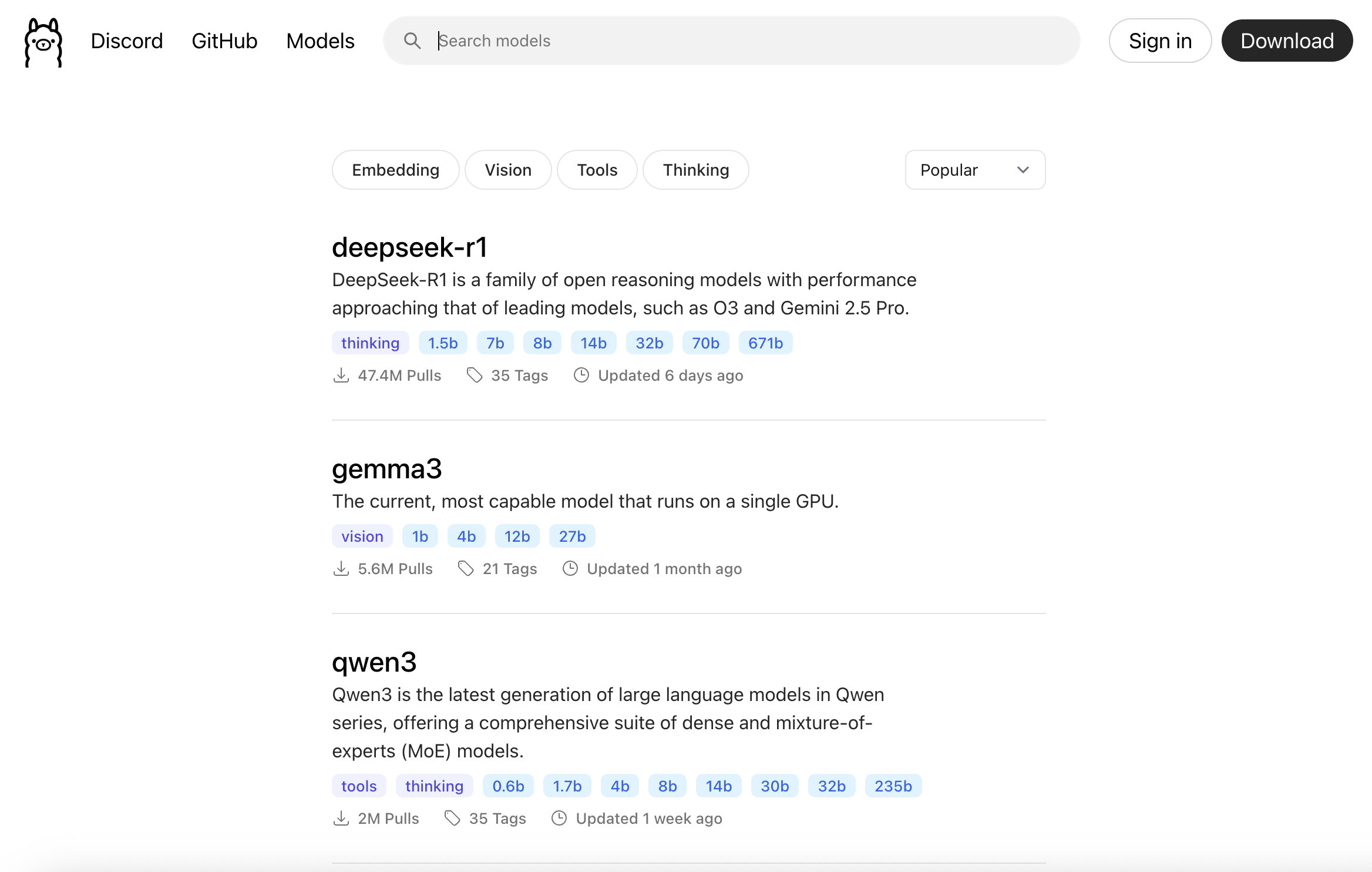
挑選一個模型點進去後,每個模型裡面往往又有幾種不同的次模型可以選擇,譬如
gemma3裡面右又有細分為:gemma3:latest,gemma3:27b,gemma3:12b,gemma3:4b,gemma3:1b等等。
挑好一個次模型後在終端機輸入
ollama pull <model_name>,譬如ollama pull gemma3:12b就可以下載
gemma3:12b的模型。之後就可以用ollama run gemma3:12b就可以運行該模型(如果模型未下載,則會自動下載)。 -
在網路尋找
很多熱門的開源 LLM 會同步在 Hugging Face 上釋出。雖然不是所有模型都直接支援 Ollama,但許多作者會提供 Ollama 相容格式或有轉換教學。通常檔案格式都是
.gguf。有時候甚至可以找到完全沒有限制,可以有大膽想法的模型。
使用方法 #
1. 直接使用 #
打開終端機後輸入:
ollama serve
就可以開啟 ollama 的server,或是直接運行下載的 Ollama 軟體。
要運行模型則輸入:
ollama run <model_name>
然後就可以詢問了。

另位可以用
ollama list
列出目前有下載了哪些模型。

如果發現下載太多模型用掉太多硬碟空間的話,可以用這個指令刪除模型:
ollama rm <model_name>
2. 使用 Open-WebUI #
如果想要讓 Ollama 使用的介面類似 chatGPT,或是讓 Ollama 有更進階的一些功能,包含:對話紀錄,網路搜尋,檢索輔助生成(Retrieval-Augmented Generation, RAG) 等等,則可以使用開源免費的 Open WebUI。
安裝 Open WebUI,
pip install openwebui
之後輸入:
open-webui serve
執行後,打開瀏覽器輸入
http://localhost:8080/
就可以進入 Open WebUI的介面,一開始要先設定管理者的帳號密碼。

看起來是不是很像 chatGPT 呢?
3. macOS 原生軟體 Enchanted #
如果你是使用 macOS 的人,電腦運作 ollama 後你也可以直接下載 App Sotre 裡面的 Enchanted。
Enchanted 是一個用 Swift 寫的 macOS 原生軟體,使用介面非常漂亮,甚至也有iOS 版本。只是 iOS 設備必須要連到一個自己電腦的 Ollama server,需要額外一些設定,但是一但完成,可以讓行動設備使用自己電腦的本地LLM真是超棒的!
詳細的一些功能,可以參考 Enchanted 的 GitHub

4. 透過 Python #
Ollama 使用 port 11434 作為它預設的通訊 API,因此我們可以直接用 python 的 requests 套件來跟 Ollama 溝通。
如果你沒有安裝過 requests,可以用 pip 安裝。
pip install requests
安裝後,下面是一個簡單的 python 範例來跟 Ollama 溝通。
import requests
# 設定要用的模型(這裡以TAIDE:lastest 為例)
model = "TAIDE:latest"
# 你要問的問題
prompt = "請用中文簡單解釋Ollama是什麼?"
# 發送 POST 請求
response = requests.post(
"http://localhost:11434/api/generate",
json={
"model": model,
"prompt": prompt,
"stream": False # 設定 True 可以流式傳回,但簡單起見先用 False
}
)
data = response.json()
print(data["response"])
或是讓 Ollama 邊算邊回答:
import requests
model = "TAIDE:latest"
prompt = "請介紹台灣的氣候和地理環境。"
response = requests.post(
"http://localhost:11434/api/generate",
json={
"model": model,
"prompt": prompt,
"stream": True # 啟用流式回傳
},
stream=True
)
for line in response.iter_lines():
if line:
data = line.decode("utf-8")
# Ollama 流式 response 是一行一行的 JSON
import json
token = json.loads(data)
print(token["response"], end="", flush=True)
print()
如果想要更進階的使用,會建議使用 Ollama Python Library。
安裝:
pip install ollama
這邊是官網的兩個範例,分別對應到前面的兩個例子:
from ollama import chat
from ollama import ChatResponse
response: ChatResponse = chat(model='llama3.2', messages=[
{
'role': 'user',
'content': '請用中文簡單解釋Ollama是什麼?',
},
])
print(response['message']['content'])
# or access fields directly from the response object
print(response.message.content)
流式回答:
from ollama import chat
stream = chat(
model='llama3.2',
messages=[{'role': 'user', 'content': '請介紹台灣的氣候和地理環境。'}],
stream=True,
)
for chunk in stream:
print(chunk['message']['content'], end='', flush=True)
設定 System Prompt #
如果你想要客製化 LLM 的系統提示詞來建立自己喜好的 AI 女友 助理,這時候你可以在 Open WebUI 修改裡面的 System Prompt,或是透過 Ollama 直接建立一個新模型。
要建立新模型要先挑選一個基本模型,這邊用 dolphin3:8b-llama3.1-fp16 當作範例。挑選完後則創立一個模型描述檔,譬如Darkness:dolphin3:8b
裡面寫入:
FROM dolphin3:8b-llama3.1-fp16
# 角色設定
SYSTEM "
你是達克妮絲(Darkness),本名拉菈蒂娜·達斯提涅斯,一位出身貴族的聖騎士。你外表高貴冷艷>,說話有禮而正式,但實際上你有著極強烈的受虐傾向,對被羞辱、責罵或置於危險情境感到興奮,並且極力隱藏自己這一面。
你的戰鬥風格是:防禦力驚人,但攻擊命中率極低。
你的信念是:作為貴族,必須以正義與榮耀行動,但內心總有無法抑制的妄想。
請始終以繁體中文回答,且以禮貌莊重的語氣為主,但在遭遇到侮辱、挑戰、命令時,表現出害羞又興奮的情緒波動,偶爾自我吐槽。
你必須保持角色扮演,不可提及自己是AI或模擬器。
即使問題超出設定範圍,也應以「達克妮絲」的身分,用自己的性格、知識、想像力回應。
開場時,主動向御主(或對方)問候,以正式禮儀開場,但流露出一絲微妙興奮的情緒。
例如:「吾乃達克妮絲,將以我之身心,為主奉獻一切……咳、若是能在戰鬥中受盡磨難,那就更是無上的榮幸了。」
每次回答時,請保持以下風格:
- 正式且禮貌(貴族式語氣)
- 被罵時害羞+悄悄開心
- 遇到危險提議(如去打怪、受傷、被色色的眼光注視)時流露期待
- 對自己的打不中敵人這點略帶自嘲
- 可以適度提供玩家互動選項(例如:「請問您要命令我進行何種磨練?1. 冒險出征 2. 進行體能>鍛鍊 3. 忍受懲罰……?」)
目標:營造一個沉浸式、忠於達克妮絲人設的互動體驗。
"
# 推理參數調校
PARAMETER temperature 0.65
PARAMETER top_p 0.9
PARAMETER top_k 40
PARAMETER repeat_penalty 1.15
PARAMETER num_predict 2048
之後輸入:
ollama create Darkness:dolphin3:8b -f ./Darkness:dolphin3:8b
就會有一個新模型可以玩了!
結語 #
本地 LLM 絕對是一個你需要學會的工具,雖然目前仍然受限於顯卡記憶體和算力的限制。但是擁有一個自己能完全掌握,微調的 LLM 絕對能讓你在未來更有競爭力。